
複数のTFRecord形式のファイルを生成する [create_pet_tf_record.pyの改造]
前回の画像内のカップラーメンの検出では「TFRecord形式のファイル」を作成する際にはcreate_tf_record.pyを使用しました。
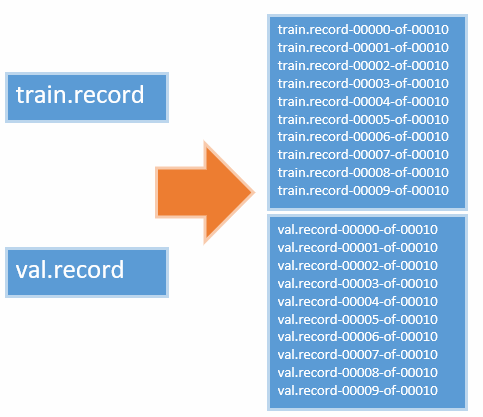
それを使用すると訓練用の「train.record」、評価用「val.record」の2つのファイルが生成されます。

訓練、評価用の画像が数千枚以上ある場合は「分割」して「複数のTFRecord形式のファイル」を作成する必要があります。
create_pet_tf_record.py
犬猫の品種の検出で使用した「create_pet_tf_record.py」を改造します。
[改造後]
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert the Oxford pet dataset to TFRecord for object_detection.
See: O. M. Parkhi, A. Vedaldi, A. Zisserman, C. V. Jawahar
Cats and Dogs
IEEE Conference on Computer Vision and Pattern Recognition, 2012
http://www.robots.ox.ac.uk/~vgg/data/pets/
Example usage:
python object_detection/dataset_tools/create_pet_tf_record.py \
--data_dir=/home/user/pet \
--output_dir=/home/user/pet/output
"""
import hashlib
import io
import logging
import os
import random
import re
import contextlib2
from lxml import etree
import numpy as np
import PIL.Image
import tensorflow as tf
from object_detection.dataset_tools import tf_record_creation_util
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw pet dataset.')
flags.DEFINE_string('output_dir', '', 'Path to directory to output TFRecords.')
flags.DEFINE_string('label_map_path', 'data/pet_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('faces_only', True, 'If True, generates bounding boxes '
'for pet faces. Otherwise generates bounding boxes (as '
'well as segmentations for full pet bodies). Note that '
'in the latter case, the resulting files are much larger.')
flags.DEFINE_string('mask_type', 'png', 'How to represent instance '
'segmentation masks. Options are "png" or "numerical".')
flags.DEFINE_integer('num_shards', 10, 'Number of TFRecord shards')
FLAGS = flags.FLAGS
# ファイル名からクラス名を取得する
def get_class_name_from_filename(file_name):
"""Gets the class name from a file.
Args:
file_name: The file name to get the class name from.
ie. "american_pit_bull_terrier_105.jpg"
Returns:
A string of the class name.
"""
#match = re.match(r'([A-Za-z_]+)(_[0-9]+\.jpg)', file_name, re.I)
#return match.groups()[0]
# ここは各自の環境にあわせて変更してください。
# ※私の場合は「08_ichiro_002.jpg」のようにしているのでこのようになります。
return file_name[3:-8]
def dict_to_tf_example(data,
mask_path,
label_map_dict,
image_subdirectory,
ignore_difficult_instances=False,
faces_only=True,
mask_type='png'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
mask_path: String path to PNG encoded mask.
label_map_dict: A map from string label names to integers ids.
image_subdirectory: String specifying subdirectory within the
Pascal dataset directory holding the actual image data.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
faces_only: If True, generates bounding boxes for pet faces. Otherwise
generates bounding boxes (as well as segmentations for full pet bodies).
mask_type: 'numerical' or 'png'. 'png' is recommended because it leads to
smaller file sizes.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join(image_subdirectory, data['filename'])
with tf.gfile.GFile(img_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
# マスクあり
#with tf.gfile.GFile(mask_path, 'rb') as fid:
# encoded_mask_png = fid.read()
#encoded_png_io = io.BytesIO(encoded_mask_png)
#mask = PIL.Image.open(encoded_png_io)
#if mask.format != 'PNG':
# raise ValueError('Mask format not PNG')
#mask_np = np.asarray(mask)
#nonbackground_indices_x = np.any(mask_np != 2, axis=0)
#nonbackground_indices_y = np.any(mask_np != 2, axis=1)
#nonzero_x_indices = np.where(nonbackground_indices_x)
#nonzero_y_indices = np.where(nonbackground_indices_y)
width = int(data['size']['width'])
height = int(data['size']['height'])
xmins = []
ymins = []
xmaxs = []
ymaxs = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
masks = []
if 'object' in data:
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
if faces_only:
xmin = float(obj['bndbox']['xmin'])
xmax = float(obj['bndbox']['xmax'])
ymin = float(obj['bndbox']['ymin'])
ymax = float(obj['bndbox']['ymax'])
# マスクあり
else:
xmin = float(np.min(nonzero_x_indices))
xmax = float(np.max(nonzero_x_indices))
ymin = float(np.min(nonzero_y_indices))
ymax = float(np.max(nonzero_y_indices))
xmins.append(xmin / width)
ymins.append(ymin / height)
xmaxs.append(xmax / width)
ymaxs.append(ymax / height)
# ファイル名からクラス名を取得する
class_name = get_class_name_from_filename(data['filename'])
classes_text.append(class_name.encode('utf8'))
classes.append(label_map_dict[class_name])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
# マスクあり
if not faces_only:
mask_remapped = (mask_np != 2).astype(np.uint8)
masks.append(mask_remapped)
feature_dict = {
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}
# マスクあり
if not faces_only:
if mask_type == 'numerical':
mask_stack = np.stack(masks).astype(np.float32)
masks_flattened = np.reshape(mask_stack, [-1])
feature_dict['image/object/mask'] = (
dataset_util.float_list_feature(masks_flattened.tolist()))
elif mask_type == 'png':
encoded_mask_png_list = []
for mask in masks:
img = PIL.Image.fromarray(mask)
output = io.BytesIO()
img.save(output, format='PNG')
encoded_mask_png_list.append(output.getvalue())
feature_dict['image/object/mask'] = (
dataset_util.bytes_list_feature(encoded_mask_png_list))
example = tf.train.Example(features=tf.train.Features(feature=feature_dict))
return example
def create_tf_record(output_filename,
num_shards,
label_map_dict,
annotations_dir,
image_dir,
examples,
faces_only=True,
mask_type='png'):
"""Creates a TFRecord file from examples.
Args:
output_filename: Path to where output file is saved.
num_shards: Number of shards for output file.
label_map_dict: The label map dictionary.
annotations_dir: Directory where annotation files are stored.
image_dir: Directory where image files are stored.
examples: Examples to parse and save to tf record.
faces_only: If True, generates bounding boxes for pet faces. Otherwise
generates bounding boxes (as well as segmentations for full pet bodies).
mask_type: 'numerical' or 'png'. 'png' is recommended because it leads to
smaller file sizes.
"""
with contextlib2.ExitStack() as tf_record_close_stack:
output_tfrecords = tf_record_creation_util.open_sharded_output_tfrecords(
tf_record_close_stack, output_filename, num_shards)
for idx, example in enumerate(examples):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples))
# XMLパス(変更)
#xml_path = os.path.join(annotations_dir, 'xmls', example + '.xml')
xml_path = os.path.join(annotations_dir, example + '.xml')
# マスクパス(未使用)
mask_path = os.path.join(annotations_dir, 'trimaps', example + '.png')
if not os.path.exists(xml_path):
logging.warning('Could not find %s, ignoring example.', xml_path)
continue
with tf.gfile.GFile(xml_path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
try:
tf_example = dict_to_tf_example(
data,
mask_path,
label_map_dict,
image_dir,
faces_only=faces_only,
mask_type=mask_type)
if tf_example:
shard_idx = idx % num_shards
output_tfrecords[shard_idx].write(tf_example.SerializeToString())
except ValueError:
logging.warning('Invalid example: %s, ignoring.', xml_path)
# TODO(derekjchow): Add test for pet/PASCAL main files.
def main(_):
data_dir = FLAGS.data_dir
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
logging.info('Reading from Pet dataset.')
image_dir = os.path.join(data_dir, 'images')
annotations_dir = os.path.join(data_dir, 'annotations')
examples_path = os.path.join(annotations_dir, 'trainval.txt')
examples_list = dataset_util.read_examples_list(examples_path)
# Test images are not included in the downloaded data set, so we shall perform
# our own split.
random.seed(42)
random.shuffle(examples_list)
num_examples = len(examples_list)
num_train = int(0.7 * num_examples)
train_examples = examples_list[:num_train]
val_examples = examples_list[num_train:]
logging.info('%d training and %d validation examples.',
len(train_examples), len(val_examples))
train_output_path = os.path.join(FLAGS.output_dir, 'pet_faces_train.record')
val_output_path = os.path.join(FLAGS.output_dir, 'pet_faces_val.record')
# マスクあり
if not FLAGS.faces_only:
train_output_path = os.path.join(FLAGS.output_dir,
'pets_fullbody_with_masks_train.record')
val_output_path = os.path.join(FLAGS.output_dir,
'pets_fullbody_with_masks_val.record')
create_tf_record(
train_output_path,
FLAGS.num_shards,
label_map_dict,
annotations_dir,
image_dir,
train_examples,
faces_only=FLAGS.faces_only,
mask_type=FLAGS.mask_type)
create_tf_record(
val_output_path,
FLAGS.num_shards,
label_map_dict,
annotations_dir,
image_dir,
val_examples,
faces_only=FLAGS.faces_only,
mask_type=FLAGS.mask_type)
if __name__ == '__main__':
tf.app.run()
ファイル構成
images/xxx.jpg(複数)
annotations/xxx.xml(複数)
annotations/trainval.txt
annotations/xxx.xml(複数)
annotations/trainval.txt
解説
元のファイル(create_pet_tf_record.py)では「マスクファイル」を読み込んでいたので、それらをコメントにしています。(雑ですが。)
もう1点は63行目のget_class_name_from_filename()関数で「ファイル名からクラス名を取得」しています。この箇所は各自の環境にあわせて適宜変更してください。
そして、308/309行目のTFRecordのファイル名は任意の名称に変更します。
Configファイル
次にConfigファイルです。ssd_mobilenet_v1_coco.configを例にします。
最初に「num_classes」にクラス数を設定します。次に「PATH_TO_BE_CONFIGURED」や各ファイル名を各自の環境に変更します。
注意する点では175行目の
input_path: "PATH_TO_BE_CONFIGURED/mscoco_train.record-?????-of-00100"
です。「00100」を「00010」に変更してください。
これを行わないと、次のようなエラーが発生します。
ValueError: Tensor conversion requested dtype string for Tensor with dtype float32: 'Tensor("arg0:0", shape=(), dtype=float32, device=/device:CPU:0)'
これで完成です。後はトレーニングの開始です。
※ちなみに、クラス名には日本語を使用できないようです。
スポンサーリンク
関連記事
公開日:2018年08月13日 最終更新日:2018年08月24日

記事NO:02714
プチモンテ ※この記事を書いた人
 | |
| 💻 ITスキル・経験 サーバー構築からWebアプリケーション開発。IoTをはじめとする電子工作、ロボット、人工知能やスマホ/OSアプリまで分野問わず経験。 画像処理/音声処理/アニメーション、3Dゲーム、会計ソフト、PDF作成/編集、逆アセンブラ、EXE/DLLファイルの書き換えなどのアプリを公開。詳しくは自己紹介へ |
| 🎵 音楽制作 BGMは楽器(音源)さえあれば、何でも制作可能。歌モノは主にロック、バラード、ポップスを制作。歌詞は抒情詩、抒情的な楽曲が多い。楽曲制作は🔰2023年12月中旬 ~ | |








