
おもちゃのAI研究室
ここはTensorFlowの「学習済みAIモデル」をWebで高速に推論できます。
どのような学習済みモデルやオープンソースが存在しているか、それらを実際に試してどう利活用できるかを検討できます。
このページは私の人工知能の研究及び学習用として製作中です。現在はアプリ数は少ないですが、目標は100個ぐらいで世界中のオープンソースのAIを紹介する予定です。サーバー側では高速化及び使用メモリ軽減、TensorFlow演算子の利用の為に、改良した「TensorFlow Lite」を使用しています。
※パソコン、スマホ、タブレットのあらゆるデバイスに対応しています。
2024/11/4~ TensorFlowのサポート期限切れの為、セキュリティ対策でAIを実行できないようにしています。

1. 画像処理















Pix2Pix



CycleGAN






U-GAT-IT



StarGAN v1/v2

Glow

DCGAN - 画像生成(低)



LightWeight-GAN - 画像生成(低~中)





StyleGAN2-ADA - 画像生成(中~高)






<Mediapipeの紹介>
これはGoogleが開発したオープンソースのMLソリューション。顔検出、フェイスメッシュ、虹彩、手、ポーズ、髪のセグメンテーション、物体検出、ボックス追跡、インスタントモーショントラッキング、Objectron(3Dオブジェクト認識)、KNIFT(特徴マッチング)などが含まれる。基本的にAndroid、C++用と思った方が良い。Pythonでも利用可能ですが使える機能が少ないです。各tfliteファイルの入力画像サイズはスマホのフロントカメラ用&高速化の為に小さいです。公式 GitHub

<顔編集系AIの紹介>
DeepFake(FaceSwap) ※GitHub
Aの顔をBの顔に入れ替える。A、B双方の画像を入手する必要がある。環境が複雑なのでColab Proを推奨。
SEAN ※GitHub
セグメンテーション(マスク)を利用した顔編集。(PyTorch)
SC-FEGAN ※GitHub
ユーザーのスケッチと色による顔編集。
PSGAN ※GitHub
元画像に参照画像のメイクアップを転送することが可能。(PyTorch)
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models(Talking Heads) ※リンク先は動画
1枚の写真から頭を動かしたり、まばたき、笑ったりなどの表情を操作する事が可能。
Transparent latent-space GAN ※GitHub
StarGANの亜種。
※その他にStarGANやGlowのように「align」(整列)は必須ですがStyleGAN 1/2でも「顔の特徴操作」(顔編集)が可能。
顔編集に関しては人工知能で「フェイスメッシュ」「顔のランドマーク」などを検出後に昔ながらの画像処理で編集する方法があります。何がなんでも機械学習で済ませる必要はありません。
<Dlib + Face Recognitionの紹介>
顔検出、顔のランドマーク、顔認識/顔認証(顔の比較、人物特定、分類)など顔に関する機械学習ライブラリ。



Colab Proでのインストール方法
# 顔認識(face_recognition)のインストール !git clone https://github.com/ageitgey/face_recognition # CMake/モデルのインストール !apt install cmake !pip install face-recognition-models # カレント %cd face_recognition
次は「顔認証」(顔の比較)のやり方です。A.pngとB.pngを比較して一致するかを行います。
# 顔認証(顔の比較)
import face_recognition
imageA = face_recognition.load_image_file("/content/A.png")
face_encoding_A = face_recognition.face_encodings(imageA)[0]
imageB = face_recognition.load_image_file("/content/B.png")
face_encoding_B = face_recognition.face_encodings(imageB)[0]
results = face_recognition.compare_faces([face_encoding_A], face_encoding_B)
print(results)
この顔の比較は「Face Distance」と記載されていますので、顔のランドマークの座標を用いた「ユークリッド距離」だと思われます。 AとBの距離が一定の閾値(デフォルトは0.6)より小さいければ顔は一致すると判断されているかと思われます。
減色アルゴリズムの「K平均法」(Kmeans)でも「ユークリッド距離」は使われます。画像を減色する際に一番近い近似色を求めるにはRGBの3次元空間の2点間の距離を求めます。計算式は次の通りです。この距離が近いものが近似色となります。
距離 = sqrt((R1- R2)^2 + (G1- G2)^2 + (B1- B2)^2)
※このユークリッド距離は計算量が多く処理に時間がかかります。
<DeepFaceの紹介>
Python用の軽量の顔認識および顔属性分析(年齢、性別、感情、人種)。ハイブリッド顔認識パッケージ。
2. 動画処理

ビデオ内で野球、バスケットボール、ピアノを弾くなどの「アクション」(動作)を認識できる。このTensorFlowチュートリアルでは101種類に対応。データセットによっては400/600/700種類に対応している。
action_recognition_with_tf_hub.ipynb(GitHub) kinetics-i3d(GitHub) kinetics-i3d(公式) 動画のライセンス
次はTensorFlowチュートリアルで「独自の動画」を使用する方法です。
video_path = 'https://upload.wikimedia.org/wikipedia/commons/transcoded/c/c0/0.2014_Reiten_auf_den_Huzulen_Pferden_in_Rudawka_am_Wis%C5%82ok.webm/0.2014_Reiten_auf_den_Huzulen_Pferden_in_Rudawka_am_Wis%C5%82ok.webm.120p.vp9.webm' sample_video = load_video(video_path)
※将来的にはアニメ制作などの制作時間短縮に期待。 tweening_conv3d.ipynb(GitHub)
| 元の2枚 |   |
|---|---|
| 補間後 |  |
今回の学習用データセット(ロジック)は「ベンジャミンバニー」(ウサギのぬいぐるみ)の場所に「ロボットアーム」か「電動ドリル」のようなものが現れて一緒に消えます。動画は64x64で画質は粗いです。
次はTensorFlowチュートリアルで「独自の写真」(2枚)を使用する方法です。
[input_framesを定義する]
from PIL import Image
img1 =Image.open('/content/オリジナル1.jpg').resize((64,64))
img2 =Image.open('/content/オリジナル2.jpg').resize((64,64))
# (2, 64, 64, 3)
aaa = np.array(img1.convert('RGB'))
bbb = np.array(img2.convert('RGB'))
ret = np.stack([aaa, bbb], 0)
print(ret.shape)
# (16, 2, 64, 64, 3)
ret = np.stack([ret,ret,ret,ret,ret,ret,ret,ret,ret,ret,ret,ret,ret,ret,ret,ret], 0)
print(ret.shape)
input_frames = tf.cast(ret, tf.float32)
[補間後の16枚を保存する]
# (16, 16, 64, 64, 3)
generated_videos = np.concatenate([input_frames[:, :1] / 255.0, filled_frames, input_frames[:, 1:] / 255.0], axis=1)
print(generated_videos.shape)
from PIL import Image
for i in range(16):
arr = generated_videos[0, i]
arr = np.array(arr) * 255
arr = np.clip(arr, 0, 255) # 0から255の範囲にする
arr = np.array(arr).astype(np.uint8) # 型変換
image = Image.fromarray(arr)
image.save('/content/'+ str(i+1) + '.png')
※上述した動作認識と似ています。動画ファイルにタグ情報などが何もない場合に活用できます。
| 元画像 | 変換動画 |
|---|---|
 |  |
今回はこれでも良い所だけを表示しています。精度は今後のAI研究者の研究次第といったところでしょうか。
articulated-animation(公式のGitHub)

3Dキャラクターを人の動きに併せてリアルタイムに動かすことが可能です。技術的には人工知能(姿勢推定 + フェイスメッシュ) + Unity(ゲームエンジン)などを組み合わせます。※これ以外にも手法はあります。
© Unity Technologies Japan/UCL
<その他>
Recycle-GAN ※GitHub
入力の「モーション」に合わせて対象を変化させる。CycleGANに時間軸を加えたもの。(PyTorch)
face2face-demo ※GitHub
入力の「モーション」に合わせて対象を変化させる。顔のランドマークを学習してPix2Pixで顔に変換する。
video-object-removal ※GitHub
動画から人物などのオブジェクトを削除する。(PyTorch)
3. 音声処理
入力する音声ファイルはWAVE形式(16kHz/モノラル)ですが、TensorFlowチュートリアルにはフォーマット変換コードが含まれています。このチュートリアルの題名は「SPICE(スパイス)によるピッチ検出」です。spice.ipynb(GitHub)
[テスト用の音声]
[VOCALOIDでの作曲風景]
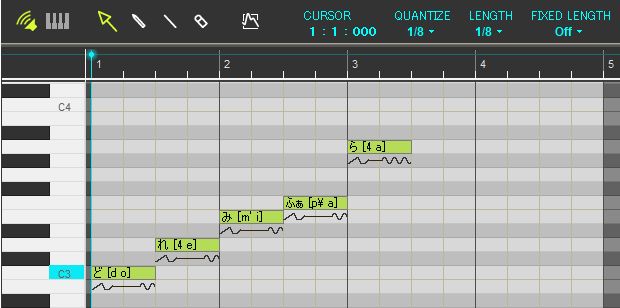
※初めの入力音はド(C3)ですが、実際は初期設定の影響で1オクターブ上のド(C4 = 261.626Hz)。
[歌声の波形]
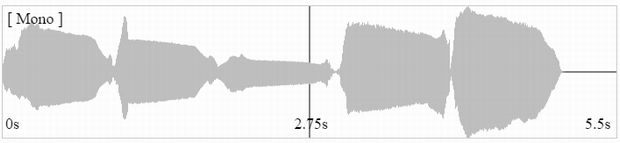
[スペクトログラムによる可視化]
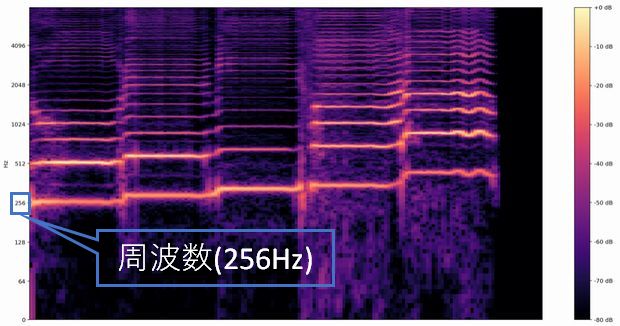

[楽譜化]

[MIDIのWAVE変換]
ブラウザでWAVE形式を変換する場合はWaveファイルのフォーマット変換。波形データと周波数スペクトルはWaveファイルの解析 / 波形データと周波数スペクトル。マイクやパソコン内の「音声」の「コード、音階、周波数(Hz)」をリアルタイムで表示するには絶対音感を参照。その他に音と周波数(Hz)の関係性を確認したい場合は各音の周波数一覧をご覧下さい。「歌、スピーチ、せせらぎ、ささやき声、拍手、ネコ、雨、滝、自動車、船、地下鉄」など521種類の分類が可能です。
※転移学習が可能ですので任意の「キーワード」や「音」を認識させる事が可能です。参照1 参照2
「up」の波形とスペクトログラム

今回の波形の横軸はサンプリング周波数(16kHz=時間経過)。スペクトログラムは時間の経過に伴う周波数の変化を示す。
スペクトログラムの一覧(例)
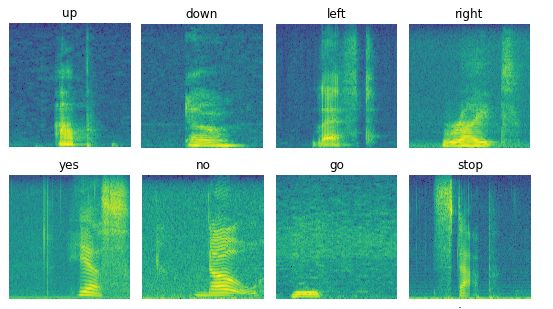
「no」(01bb6a2a_nohash_0.wav)の認識結果

<音声変換>
CycleGAN-VC ※GitHub
音声変換、男女声変換、声質変換 ※事前訓練済みモデルはファイル欠落。
CycleGAN-VC2 ※GitHub
音声変換、男女声変換、声質変換 (PyTorch)
CycleGAN-VC3 ※GitHub
音声変換、男女声変換、声質変換 (PyTorch)
MaskCycleGAN-VC ※GitHub
音声変換、男女声変換、声質変換 (PyTorch)
StarGAN-VC ※GitHub
音声変換、男女声変換、声質変換 (PyTorch)
StarGAN-VC2 ※GitHub
音声変換、男女声変換、声質変換 (PyTorch)
人工知能による音声変換に関してはNTTコミュニケーション科学基礎研究所のページで各変換済みの音声を確認可能です。これらを応用すれば歌声、美女声、アニメ声、イケボ(イケメンボイス)などにも変換可能と思われます。
<Magentaの紹介>
Magenta Magentaデモ
元々はGoogle Brainチームが手掛けていたが現在は様々のエンジニアが参画。
Magenta.js ※必見!
Music Transformer(AIによる作曲)、機械学習ドラマー、NSynthサウンドメーカー(楽器合成)、AIデュエットなど多数。
Transformerでピアノ音楽を生成する (Colabノートブック)
AIによる作曲の例 - MP3(32kbps) 160KB ※高圧縮低品質
※これはファイルサイズを極限まで小さくしていますので低品質です。高音質版(16bit 48000Hz ステレオ / 7.45MB)
<その他>
めえめえ - AI自動作曲
歌詞を入力するだけで自動的に作曲してくれる自動作曲システム。
ぱぴー[AI音楽家]
AIで作成した1000曲以上の「ピアノ曲、BGM、歌」の音楽(MP3)がダウンロード可能。
4. 自然言語処理(NLP)
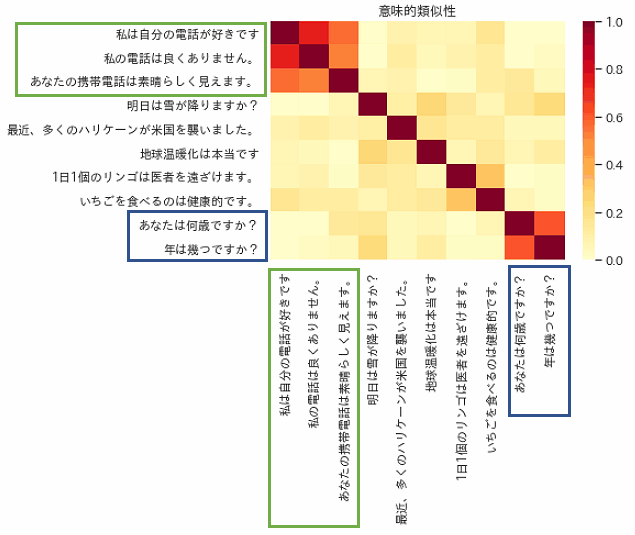
次の図は意味的類似性。わかりやすいように青色、緑色で囲んでいます。1.0に近いほど類似度が高い。
TensorFlowチュートリアルは英語のみです。日本語を含む16言語で利用する場合は下記を参考にして下さい。
# USE(多言語版)で必須のライブラリ
!pip3 install tensorflow_text>=2.0.0rc0
# Seaborn/matplotlibの日本語フォント対応
!pip3 install japanize-matplotlib
# インポート
import japanize_matplotlib
import tensorflow_text
# ハブのロード
model = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
# 日本語フォントの設定
...
sns.set(font='IPAexGothic')
...
# ここに日本語の文を設定する
messages =[]
USE(英語のみ) USE(多言語対応版)
※TensorFlowチュートリアルの原題は「TPUでBERTを使用してGLUEタスクを解決する」です。
[8種類の課題]
| CoLA | 文は文法的に正しいか? |
|---|---|
| SST-2 | 文の感情を予測する。 |
| MRPC | 文のペアが意味的に同等であるかどうかを判断する。 |
| QQP | 質問のペアが意味的に同等であるかどうかを判断する。 |
| MNLI | 前提文と仮説文が与えられた場合、前提が仮説を伴うか(含意)、仮説と矛盾するか(矛盾)、どちらでもないか(中立)を予測する。 |
| QNLI | 文に質問への回答が含まれているかどうかを判断する。 |
| RTE | 文が特定の仮説を伴うかどうかを判断する。 |
| WNLI | 代名詞が置換された文が元の文に含まれているかどうかを予測する。 |
次に「Connect to the TPU worker」(TPUワーカーに接続する)のコードを次のように変更します。
import os
strategy = tf.distribute.MirroredStrategy()
print('Using GPU')
この8種類の課題は課題毎にトレーニングをする必要があります。
※SST-2のトレーニング時間は「Tesla V100-SXM2」で約30分かかります。「Tesla P100-PCIE」だとその約3倍。
全て実行したら末尾に次の2個の「推論用コード」を追加して実行します。
with tf.device('/job:localhost'):
serving_model = reloaded_model.signatures['serving_default']
xxx ={"sentence":tf.constant("I like apples.")}
result = serving_model(**xxx)
print_bert_results(list(xxx.values()), result['prediction'], tfds_name)
with tf.device('/job:localhost'):
serving_model = reloaded_model.signatures['serving_default']
xxx ={"sentence":tf.constant("I not like apples.")}
result = serving_model(**xxx)
print_bert_results(list(xxx.values()), result['prediction'], tfds_name)
次は「文」を変えて試した結果です。
// I am an angel. (私は天使です。) This sentence has POSITIVE sentiment. // I am a devil. (私は悪魔です。) This sentence has NEGATIVE sentiment. // I am a good boy. (私は良い子です。) This sentence has POSITIVE sentiment. // I am a bad boy. (私は悪い子です。) This sentence has NEGATIVE sentiment. // I am normal. (私は普通です。) This sentence has POSITIVE sentiment.
retrieval_with_tf_hub_universal_encoder_qa.ipynb
次のように「質問」と「回答」を指定して実行すると「補足文」が返る。
num_results = 5 query =[ "学校ではどの言語で教えていますか?", # 質問 "英語" # 回答 ] display_nearest_neighbors(query[0], query[1]) # 以下は質問のみの場合 # display_nearest_neighbors(query[0])
※display_nearest_neighbors()に渡すのは質問のみでも可能です。
※補足文に関しては「データセットのJSON」(squad_url)の中身を日本語で編集する必要があるかも知れません。
tf2_semantic_approximate_nearest_neighbors.ipynb

<その他のチュートリアル(コア)>
単語埋め込み(単語の分散表現) ※基礎
Word2Vec ※基礎
RNNを使用したテキスト分類
BERTモデルの微調整
RNNによるテキスト生成
アテンションを用いたニューラル機械翻訳 ※日本語(jpn-eng.zip)
画像キャプション
言語理解のためのTransformerモデル
<その他のチュートリアル(Hub)>
映画レビューを使用したテキスト分類(二項分類)
BERTを使用したテキスト分類(感情分析)
BERTエキスパート(意味的類似性)
Kaggleでのテキスト分類
ベンガル語の記事分類
CORD-19テキスト埋め込みの詳細
多言語 Universal Sentence Encoder
テキストクックブック
<その他のチュートリアル(Lite)>
BERT質問応答
スマートリプライ ※会話型チャットメッセージ
テキスト分類
5. その他
<チュートリアル(強化学習)>
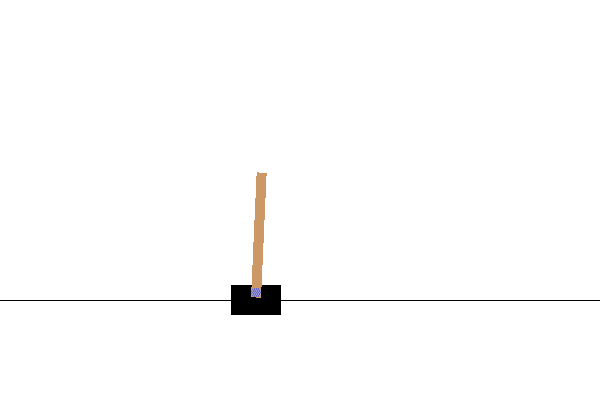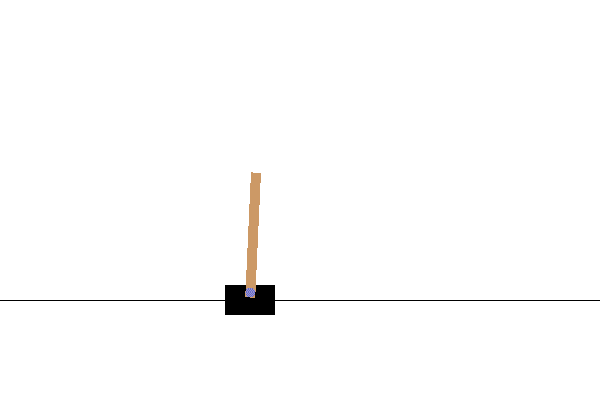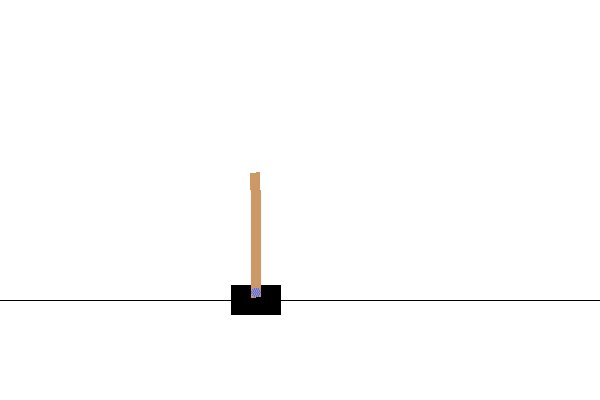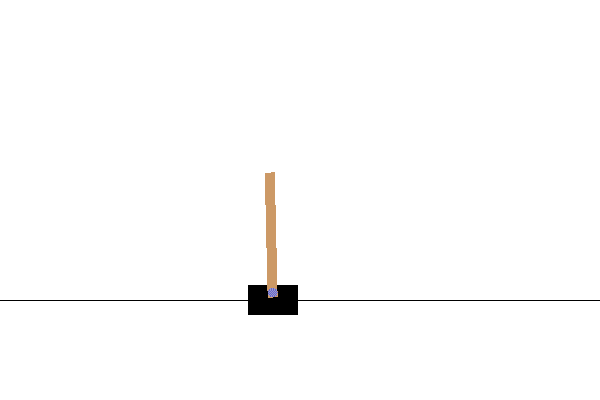
CartPole
黒いカート(荷車)の上にある「ポール」(茶色の棒)が倒れないように移動する。
<チュートリアル(Lite)>
研究・学習環境
| ・Intel Core i5-8400 CPU@2.80GHz |
| ・Main Memory 32GB |
| ・GeForce GTX 1080 Ti (11GB) |
※上記以外にColaboratory Proを契約中(月額1072円)。Tesla V100-SXM2やTesla P100-PCIEなどを利用。
お役立ちリンク
<公式>
TensorFlow コア(チュートリアル)
TensorFlow Hub(チュートリアル)
TensorFlow Hub(モデル)
TensorFlow Lite(チュートリアル)
TensorFlow Lite(アプリの例)
TensorFlow Agents(チュートリアル) ※強化学習用ライブラリ
TensorFlow.js(チュートリアル) ※JavaScriptなので処理速度に注意
TensorFlow.js(モデル) ※JavaScriptなので処理速度に注意
<非公式>
Awesome TensorFlow Lite ※tfliteファイルの情報まとめ
人工知能、実世界DB ※福山大学/大学院(情報系)の「金子邦彦研究室」
顔認証AIの仕組みを解説
CelebA データセットから好みのデータセットを抽出する
「日本は機械学習パラダイス」その理由は著作権法にあり
機械学習で利用できる各データセットの一覧
自己紹介(作品集)
https://www.petitmonte.com/app/
運営者ブログ