
正規表現のまとめ[+セキュリティ対策]
開発現場では主に妥当性チェックで使用される正規表現ですが、ほとんどのケースでクラスや関数化されていて正規表現のパターンを学ぶ機会は少ないと思います。と言うことで正規表現の基本的な使い方をまとめてみました。
また、正規表現の「セキュリティ対策」についても解説したいと思います。
正規表現の関数
PHPの代表的な正規表現の関数は次の3つとなります。
| 関数 | 用途 |
|---|---|
| preg_match | 正規表現によるマッチングを行う ※マッチング = 対象文字列がパターンに一致するかどうか |
| preg_replace | 正規表現検索および置換を行う |
| preg_match_all | 繰り返し正規表現検索を行う |
※PCRE(Perl Compatible Regular Expressions)は日本語にすると「Perl互換正規表現」です。C言語で実装したライブラリでLinux、ApacheやPHPなどで使用されています。
preg_match()の使い方
[構文]
[引数]
| 引数 | 意味 |
|---|---|
| $pattern | パターン |
| $subject | 対象文字列 |
| &$matches | [省略可能]検索結果が配列で代入される |
| $flags | [省略可能]フラグの設定(初期値0) |
| $offset | [省略可能]検索開始位置の指定(初期値0) |
[戻り値]
| 戻り値 | 意味 |
|---|---|
| 1 | 一致(マッチ)した場合 |
| 0 | 一致(マッチ)しない場合 |
| FALSE | エラーが発生 |
使用例1 - 妥当性チェック
// 数字チェック
function isNumeric($str){
if (preg_match("/\A[0-9]+\z/",$str)) {
return TRUE;
} else {
return FALSE;
}
}
// 英数字チェック
function isAlphabetNumeric($str){
if (preg_match("/\A[a-zA-Z0-9]+\z/",$str)) {
return TRUE;
} else {
return FALSE;
}
}
if (isNumeric(123))
echo "一致しました。<br />";
else
echo "一致しません。<br />";
if (isAlphabetNumeric("abc123ABC"))
echo "一致しました。<br />";
else
echo "一致しません。<br />";
if (isAlphabetNumeric("あいうえお"))
echo "一致しました。<br />";
else
echo "一致しません。<br />";
[結果]
一致しました。 一致しました。 一致しません。
※パターンに「^」「$」でなく、「\A」「\z」を使用しているのはセキュリティ上の対策です。詳細は後述します。
使用例2 - 検索結果を取得
preg_match("/[a-zA-Z]+/","あいうFishえお",$matches);
echo "<pre>";
var_dump($matches);
echo "</pre>"
[結果]
array(1) {
[0]=>
string(4) "Fish"
}
パターンの構文
まずはサンプルの「パターン」を見てください。
次のパターンは対象文字列が「あいうえお」のいずれかの文字にマッチするかどうかです。わかりやすいように正規表現のデリミタや文字クラス、メタ文字などの用語を図解で表示しています。
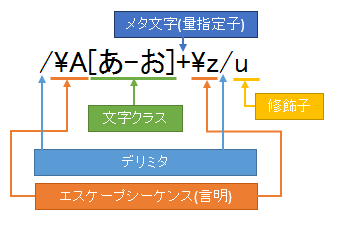
デリミタ
パターンはデリミタで囲む必要があります。デリミタには英数字、バックスラッシュ、空白文字以外の任意の文字を使用します。一般的に使用されるのは「/」(スラッシュ)です。その他には「#」(ハッシュ記号)、「~」(チルダ)、「%」(パーセント)なども使用可能です。
/[0-9]+/
#[0-9]+#
%[0-9]+%
※特殊な場合を除きデリミタには「/」を使用するのが望ましいです。
修飾子
修飾子はデリミタの後ろに指定します。必ずしも記述する必要はありません。
| 修飾子 | 意味 |
|---|---|
| i | 大文字と小文字を区別しない |
| u | パターンと対象文字列をUTF8として扱う |
// 大文字小文字を区別しない英字
/[a-z]+/i
// あ~おのUTF8のひらがな
/[あ-お]+/u
※日本語(UTF8)の文字列が含まれる場合は必ず「u」を記述します。
メタ文字
メタ文字は角カッコ[ ]の外で使用できるものと角カッコ内で使用できる2種類あります。次のメタ文字は角カッコの外で使用できるものです。
| メタ文字 | 意味 |
|---|---|
| ^ | 行頭 |
| $ | 行末(改行含む) |
| . | 改行を除く全ての文字 |
| [] | 文字クラス |
| | | OR (論理和) |
| () | サブパターン |
| {} | 量指定子(最長一致) |
| {}? | 量指定子(最短一致) |
| \ | エスケープ文字 |
文字クラス
文字クラスはパターンに記述する角カッコ[ ]の事です。
| 例 | 意味 |
|---|---|
| [abc] | abcのいずれかにマッチ |
| [^abc] | abc以外にマッチ |
| [0123456789] | 0から9のいずれかにマッチ |
| [0-9] | 0から9のいずれかにマッチ |
| [^0-9] | 0から9以外にマッチ |
| [a-zA-Z] | 英字のいずれかにマッチ |
| [a-zA-Z0-9] | 英数字のいずれかにマッチ |
| /[あ-お]/u | あ~おのいずれかにマッチ |
※「^」「-」「\」は角カッコ内で使用できるメタ文字となります。
サブパターン
サブパターンは丸カッコで括ります。論理和の「|」と一緒に使用されます。
パターン
[対象文字列1]
[結果]
結果:一致します。 $matches[0] = 猫は魚が好きです。 $matches[1] = 魚
[対象文字列2]
[結果]
結果:一致します。 $matches[0] = 猫はねずみが好きです。 $matches[1] = ねずみ
[対象文字列3]
[結果]
結果:一致しません。
量指定子
量指定子は「繰り返し」を記述します。
| 量指定子 | 意味 | 補足 |
|---|---|---|
| * | 0回以上の繰り返し | {0,}の省略形 |
| + | 1回以上の繰り返し | {1,}の省略形 |
| ? | 0または1回の出現 | {0,1}の省略形 |
| {n} | n回の繰り返し | |
| {n,} | n回以上の繰り返し | |
| {n,m} | n回以上、m回以下の繰り返し |
※量指定子の「n」「m」には回数を意味する数字を設定します。
最長一致と最短一致
最長一致は正規表現のデフォルトの仕様です。複数の検索結果の中で最も長い文字を返します。最短一致は量指定子の「?」を記述する事により最も短い文字を返します。
[対象文字列]
[最長一致のパターン]
[結果]
結果:$matches[0] = petitmont
「/.+t/」のパターンの意味は「改行を除く全ての文字」が「1回以上の繰り返し」で最後の文字が「t」です。ですので「petitmonte」が一致します。
[最短一致のパターン]
[結果]
結果:$matches[0] = pet
「/.+?t/」のパターンの意味は「改行を除く全ての文字」が「1回以上の繰り返し」で最後の文字が「t」です。条件としては「?」が含まれていますので最短一致となります。ですので「petitmonte」が一致します。
エスケープシーケンス
エスケープシーケンスは基本的にエスケープしたい文字の前に 「\」(バックスラッシュ)を記述してエスケープ文字として使用します。それ以外の用途としては「制御コード」や「文字型」「言明(げんめい)」となります。
エスケープ文字
| エスケープ文字 | 意味 |
|---|---|
| \* | * |
| \+ | + |
| \? | ? |
| \/ | / |
| \^ | ^ |
| \$ | $ |
| \\ | \ |
制御コード
| 制御コード | 意味 |
|---|---|
| \n | 改行(16進 0A) |
| \r | キャリッジリターン (16進 0D) |
| \t | タブ(16進 09) |
文字型
| 文字型 | 意味 | 補足 |
|---|---|---|
| \d | 数字 | [0-9]と同じ |
| \D | 数字以外 | [^0-9]と同じ |
| \w | 英数字アンダーバーの単語 | [_a-zA-Z0-9]と同じ |
| \W | 英数字アンダーバーの単語以外 | [^_a-zA-Z0-9]と同じ |
言明
| 言明 | 意味 |
|---|---|
| \A | 行頭 |
| \z | 行末(改行含まず) |
※エスケープシーケンスは基本的に文字クラス内外で使用可能ですが「言明」については文字クラス内では使用できません。また、エスケープシーケンスは大文字小文字によって意味が異なりますので注意して下さい。
正規表現のセキュリティ(脆弱性対策)
Rubyで正規表現のパターンの行頭に「^」行末に「$」を使用すると「SQLインジェクション」などの致命的な脆弱性となります。
※詳細は徳丸浩の日記(外部サイト)をご覧ください。
PHPやPerlの場合は数値や文字列に「改行コード」が含まれてしまう脆弱性となります。(比較的安全ですが対応するべきだと思います。)
PHPやPerl、Rubyなどの言語でこの脆弱性を対策するには
[検証コード]
$str = "123" . "\n";
// メタ文字による行頭行末の記述
if (preg_match("/^[0-9]+$/",$str))
echo "[メタ文字]一致しました。<br />";
else
echo "[メタ文字]一致しません。<br />";
// 言明による行頭行末の記述
if (preg_match("/\A[0-9]+\z/",$str))
echo "[言明]一致しました。<br />";
else
echo "[言明]一致しません。<br />";
[結果]
[メタ文字]一致しました。 [言明]一致しません。
PHPなどの書籍やインターネット上にあるサンプルには正規表現のパターンに「^」「$」を使用しているものが非常に多いです。正規表現のセキュリティホールの情報が広がると良いですね。
※この対策は一行テキスト用です。textareaタグなどの複数行で改行が必要なテキストには向いていませんのでご注意ください。
参考サイト
パターン構文 (PHP公式)
正規表現(PCRE)の関数 (PHP公式)
正規表現チェッカー ver3.0
関連記事

プチモンテ ※この記事を書いた人
 | |
| 💻 ITスキル・経験 サーバー構築からWebアプリケーション開発。IoTをはじめとする電子工作、ロボット、人工知能やスマホ/OSアプリまで分野問わず経験。 画像処理/音声処理/アニメーション、3Dゲーム、会計ソフト、PDF作成/編集、逆アセンブラ、EXE/DLLファイルの書き換えなどのアプリを公開。詳しくは自己紹介へ |
| 🎵 音楽制作 BGMは楽器(音源)さえあれば、何でも制作可能。歌モノは主にロック、バラード、ポップスを制作。歌詞は抒情詩、抒情的な楽曲が多い。楽曲制作は🔰2023年12月中旬 ~ | |
オリジナルゲームをつくってみました✨
Peasant Samurai ~ 百姓ノ持チタル国 (2026/8/3 公開予定)https://store.steampowered.com/app/4880700/Peasant_Samurai/
「民」が主役の幻想戦国RTS/街づくりゲーム






